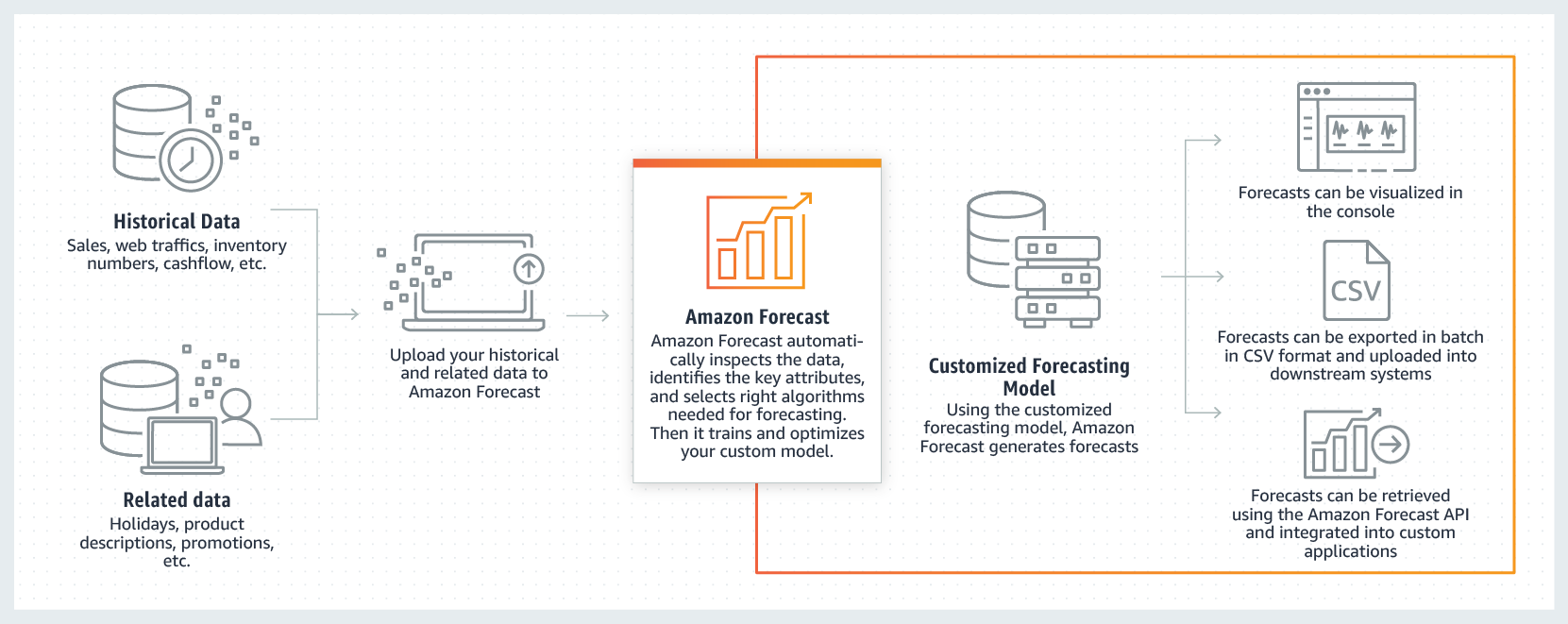
CI/CD(継続的インテグレーション/継続的デリバリー, continuous integration/continuous delivery)に移行すると、デプロイしたビルドのモニタリングや問題解決が忙しくなる。次のデリバリーマイルストーンに行ったあとに問題に対応するには、どうしたらいいのか?。昨年、AppDynamicsのファウンダーJyoti Bansalが立ち上げたスタートアップHarnessはそれを、24×7 Service Guardと呼ばれるツールで解決しようとする。
このツールは、すべてのビルドを、それらがいつローンチされたものであってもモニタすることによって、継続的デリバリーの工程を支える。そのためにはAIと機械学習を利用して、問題のあるビルドを自動化でうまくいっていたビルドに遡及(後戻り)させ、デベロッパーとオペレーションが心配なく仕事を続けられるようにする。
同社は昨年、継続的デリバリーのビルドがデプロイされたことを検証(verify)するContinuous Verificationというツールをローンチした。今日(米国時間12/13)の発表でBansalは、同社はそれをレベルアップすることによって、デプロイ後に何が起きたのかを理解するためのツールに仕立てた、と言っている。
そのツールは毎回のビルドを、デプロイから数日経ったものであってもウォッチし、そしてAppDynamicsやNew Relic, Elastic, Splunkなどのツールからのデータを利用、さらにAIと機械学習を使って問題を特定し、人間の介入なしでそれらを実動状態に戻す。さらにまた、ユーザーのチームは、さまざまなモニタリングツールやロギングツールのデータから得られた、各回のビルドのパフォーマンスとクォリティの統一的なビューを取得できる。
Bansalはこう説明する: “みんな継続的デリバリーで苦戦している。これまでも彼らは、AIを使ったOpsツールでプロダクションに入ったものをウォッチし、問題を究明しようとしてきた。でもうちのやり方では、CD段階のウォッチにAIを使うことによって、プロダクションの段階には問題がないようにする”。
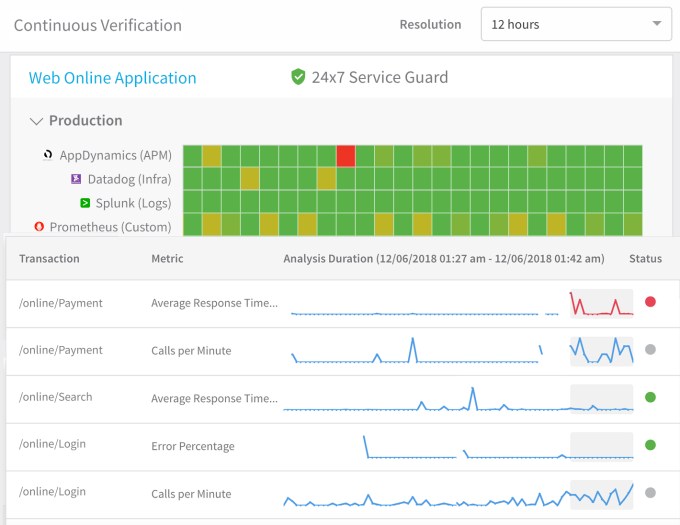
24×7 Service Guardのコンソール。スクリーンショット提供: Harness
彼によると、このプロダクトを商用化したのは、CI/CDで苦戦している企業をたくさん見てきたからだ。彼は言う: 速く動くことによって問題の露呈を早くする、というCI/CDの初期の教えはエンタープライズに通用しない。彼らに必要なのは、ミッションクリティカルなアプリケーションが継続的ビルド(その定義はさておき)でも動き続けることだ。
“デベロッパーは速く動いてしかも会社の業務がその影響を受けないようにしたいのだ。だから、あの初期の教えでは不十分なんだよ”、と彼は語る。
どんなプロダクトにもアップタイムの絶対的な保証はできないがこのツールは、CI/CDに価値を見出しているがアプリケーションは動かし続けたい、という企業の役に立つ。デプロイしてから修復するというワンパターンを、繰り返したくない。このツールが本当に役に立てば、CI/CDを前進させるだろう。とくにそれは、開発工程を迅速化したいけど、アプリケーションが壊れないという確証がほしい、問題の修復は自動化したい、という大企業に向いている。